居然都找不到!
其实Blog我主要是用来做一些记录,更何况忙起来经常不更新,因此尽管有加上一些流量统计的功能,但实际上也不怎么关心到底有多少访问量。在浏览网上其他人的博客布局寻找灵感时,突然看到有博客提到GitHub Pages屏蔽了百度的爬虫,所以百度是搜索不到GitHub Pages上的网页的。
什么?所以百度搜索搜不到我的个人博客?不死心,尝试一下,找得到github、gist主页,但是就是找不到github.io后缀的网页。除了百度之外,我还尝试了Bing、Google,都没有,所以常用的三大搜索引擎都找不到我的博客,小小网站在浩瀚的网络世界中就像是一个孤岛,只有知道url才能达到。突然想到传说中的暗网是否也是加上了反爬,所以大众难以发现?
话说回来,反爬也有反爬的好处,比如有时博客内容特别个人,只是想找个地方发泄一下、记录一下,不被搜索引擎索引到也降低了被他人发现的几率,就像是一个打开的日记本,但是不用担心被家长偷看的感觉。
如何让搜索引擎索引到呢?
发现流行的搜索引擎居然都找不到博客,那就需要赶紧找解决方法。Google和Bing还不清楚是怎么回事,但网上流传的email回复内容都点明了Github Pages禁止了百度爬虫的爬去,似乎原因是百度爬虫爬得太过于频繁,会严重影响服务器性能。针对百度爬虫的问题,大家找了很多方法。比较早期的有把放在GitHub上的代码同时push到国内的GitCafe上,但GitCafe已经被Coding.net收购,2017年6月前很多方案都是同步推送到Coding.net上,而8月开始免费的Coding.net用户会被强行加入5s等待页面,也会导致爬取失败。自建服务器托管博客、将博客放在Gitlab上或者CDN方法都不在我的选择范围内,因为暂时我还没有购买服务器或者域名的打算,所以决定放弃百度……但不管怎么样Bing和Google还是要设置好的!
居然在robots.txt中设置了屏蔽!!!
我对网络、网站这部分并不熟悉,之前在了解themes里内容时有看见过这么个小小的txt文件,并没有放在心上,但原来各个爬虫爬不到罪魁祸首就在这个txt文件上。
robots.txt在网站的根目录里,文件中明确了爬虫可以爬取以及禁止收录的范围。搜索引擎爬取网站第一个访问的文件就是robots.txt。robots.txt中可以对于不同的搜索引擎机器人设置不同的权限,这里就不赘述了,毕竟也不是我关心的重点^-^。
Hugo在static文件夹中就有一个robots.txt,生成静态网页时就会把这个文件放在网站的根目录下。默认的robots.txt如下所示:
User-agent: *
Disallow: /
第二行把所有爬虫都给屏蔽了,只需要把第二行的 / 删去就ok了。
尽管已经修正了robots.txt,但是过了一天多看各个搜索引擎,还是找不到我的博客网站,所以还是要进一步处理。
添加资源
在google搜索页面输入“site:orianna-zzo.github.io”就可以看到这个网页是否被google索引到,如果没被索引到,在搜索结果页面就会直接提示你使用Google Search Console。登录后,如果是首次使用在Search Console中以下界面中选择“网页”类型资源,并将博客完整url填入其中,我填入“https://orianna-zzo.github.io”。注意http或者https,www等最好能完全正确。
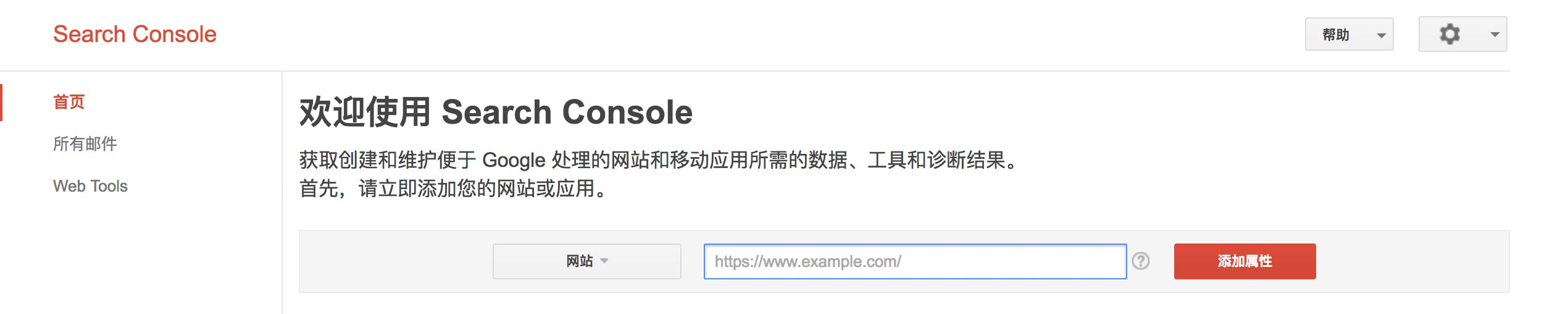
如果已经添加过资源,则需要点击下面的红色按钮“添加属性”,然后和上面一样地添加资源即可。

资源添加后,需要验证你对该网站有所有权。Google提供了几种方法,我选择了HTML验证文件上传,只需要根据要求,下载HTML验证文件,把文件放在网站的repository中上传,然后进行验证即可。
查看robots.txt
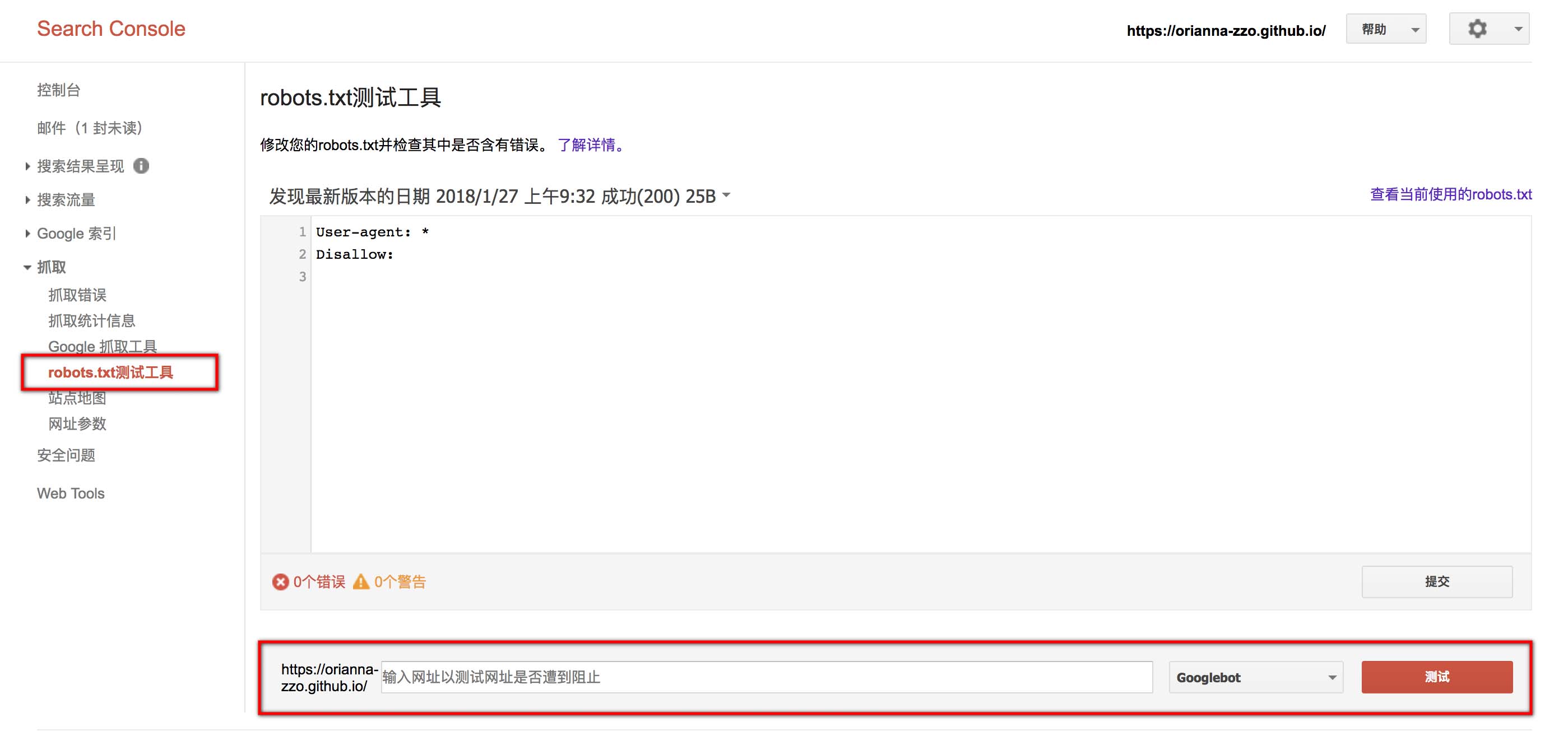
资源添加后,先查看robots.txt是否设置正确。我就是在这里才发现在这个文档中把所有搜索引擎的爬虫机器人都屏蔽了。
进入资源后,在左侧点击“抓取>robots.txt测试工具”,右边会有显示robots.txt的内容。需要注意的是,robots.txt并不一定是最新版的,看上去这个每天只会更新一次。可以在下方输入需要测试的网址,并点击测试。若显示已允许则说明设置ok。
添加url
robots.txt设置成功还是不够的,还是需要手动添加url。在左侧点击“抓取>Google抓取工具”,在右侧金融人机身份验证后,可以将想要添加的url写入输入框,并进行抓取。
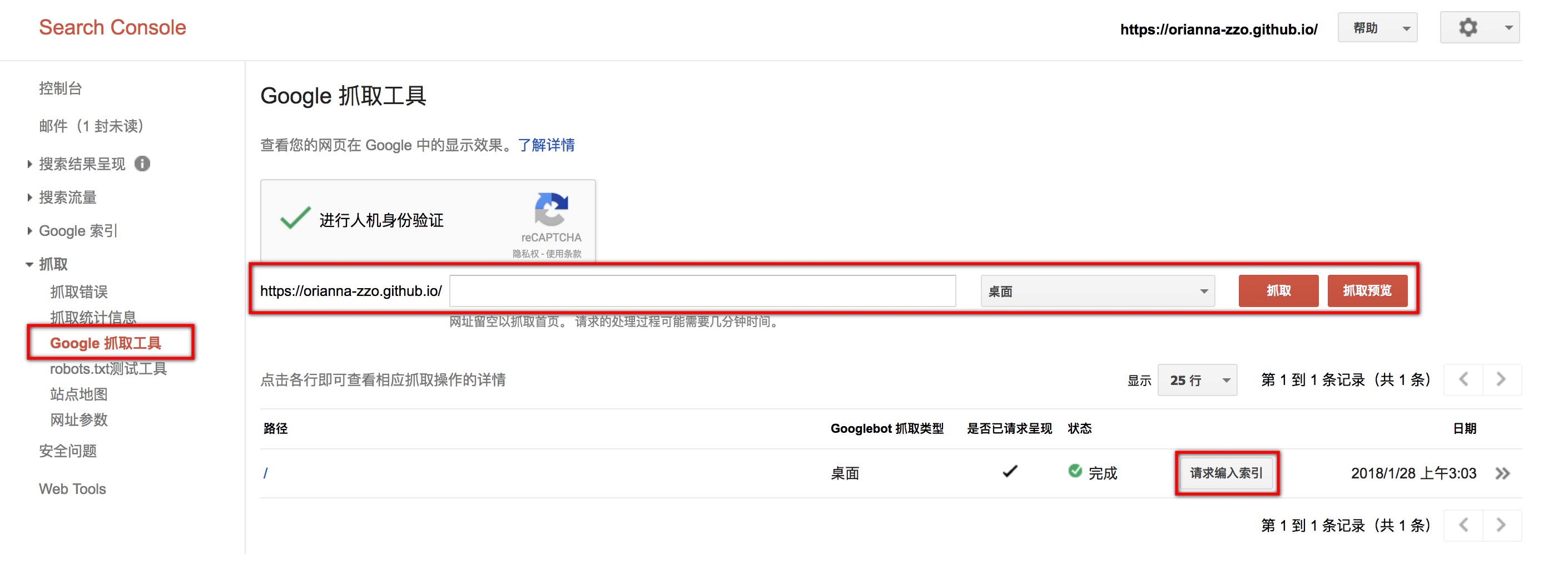
状态显示完成,说明该网页已经爬取成功。点击“请求输入索引”,会显示以下选择框:
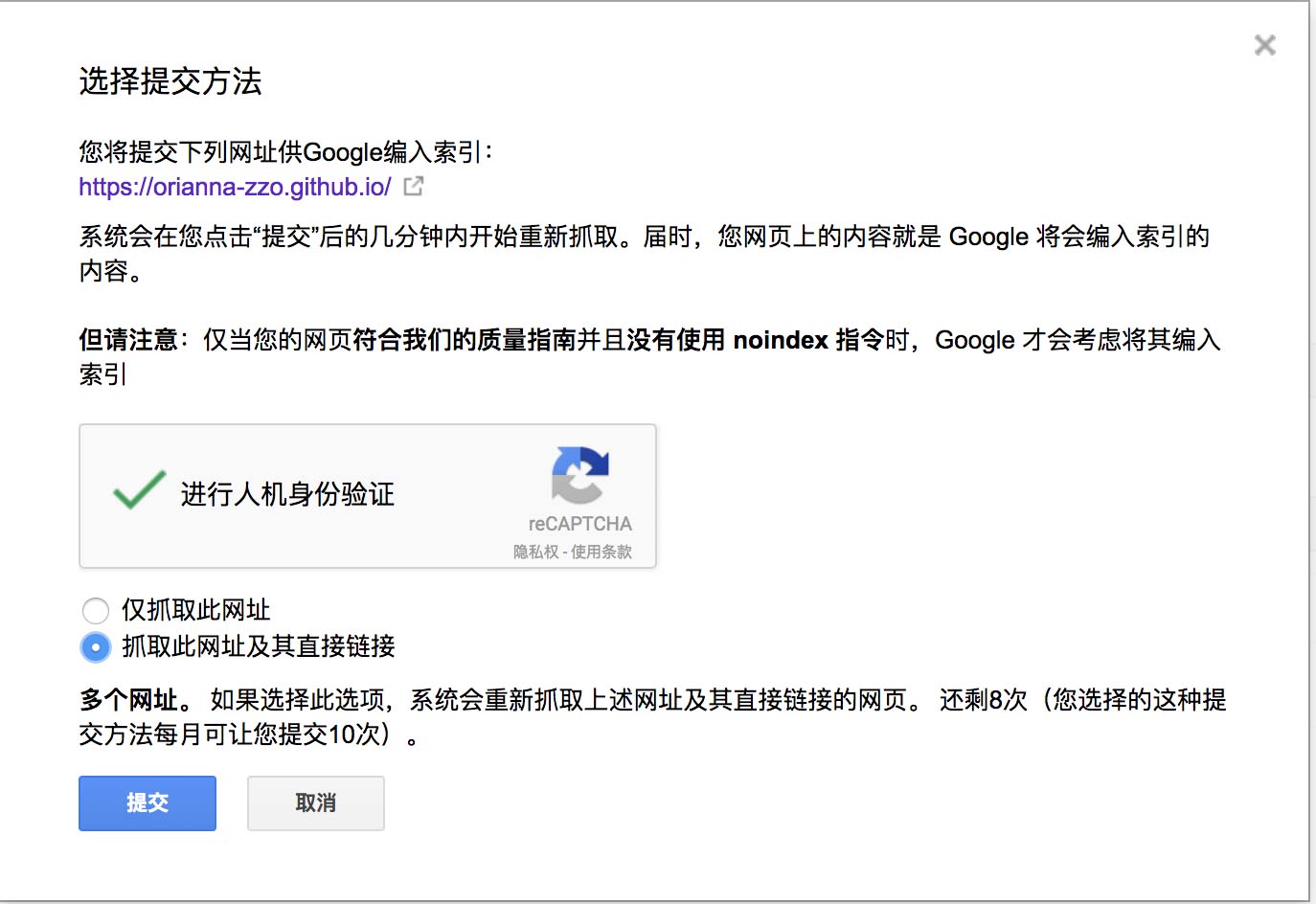
有两个选项,第一个仅抓取次网址,每个月500次提交机会,第二个抓取次网址及其直接链接,每个月有10次提交机会。提交后,编入了索引,等上一会就可以在google上搜索了!
不过提交次数多就需要进行图片验证,而且如果网站有修改就需要重新提交。鉴于现在内容不多,先都是人肉提交的,如果网页多的话,可以通过站点地图进行提交。
站点地图
在左侧点击“站点地图”,并在右侧点添加/测试站点地图,并添加url,我的是“https://orianna-zzo.github.io/sitemap.xml”。
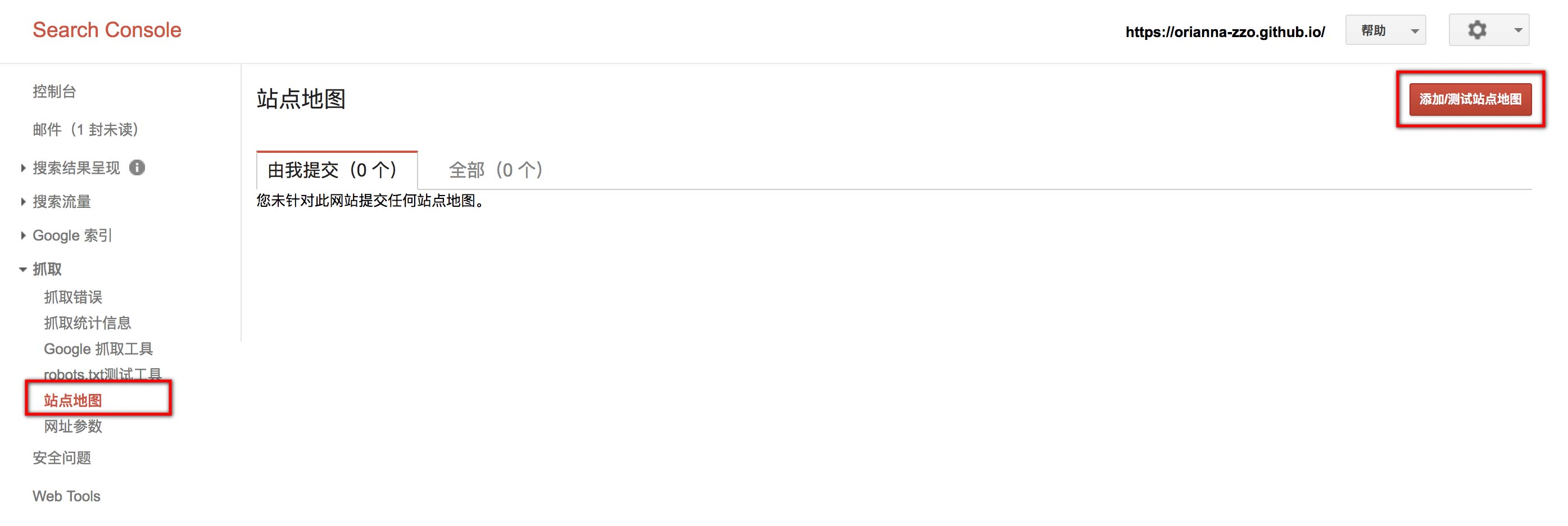
发现提示有警告,说是网址遭到robots.txt阻止。原来sitemap需要在robots.txt增加配置,于是现在robots.txt如下所示:
User-agent: *
Disallow:
Sitemap: https://orianna-zzo.github.io/sitemap.xml
要注意的是,如果有网页不想被爬取,不仅需要在robotx.txt中注意增加在Disallow后面,还要注意生成sitemap时不要添加进去。
Bing
相似地,在Bing网站管理登陆、添加网站url。
然后在左侧点击“配置我的网站>Sitemaps”,并在右侧加上sitemap的url,点击提交。

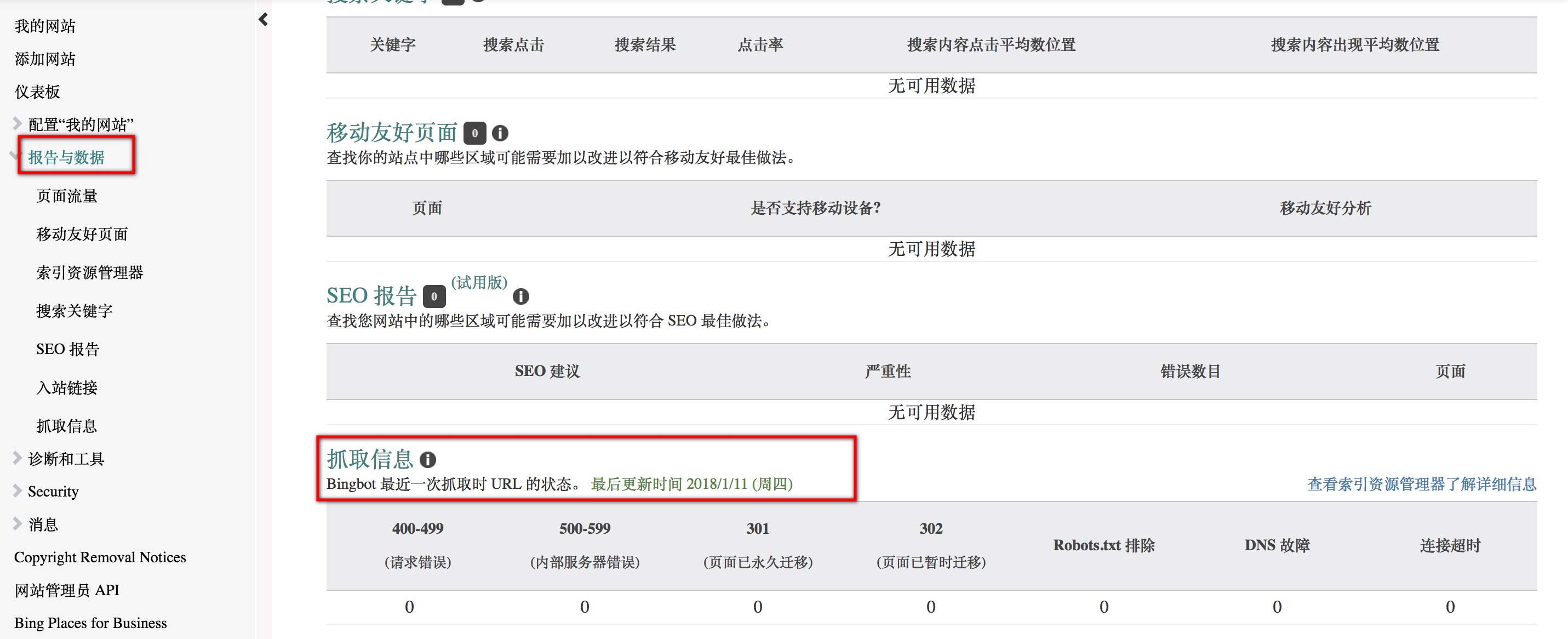
Google基本过一天就能查到,但是Bing我总是很难搜索到,猛然发现上次抓取更新时间还在1-11,已经过了大半个月了,不知道什么时候才能知道效果了。
百度不死心的尝试
百度在这里注册站长管理并添加网站资源,我同样选择添加HTML文件。注意http或者https、www等最好能完全正确。我百度的验证过好几次都没有成功,料想是将https写成了http所以验证出现问题。
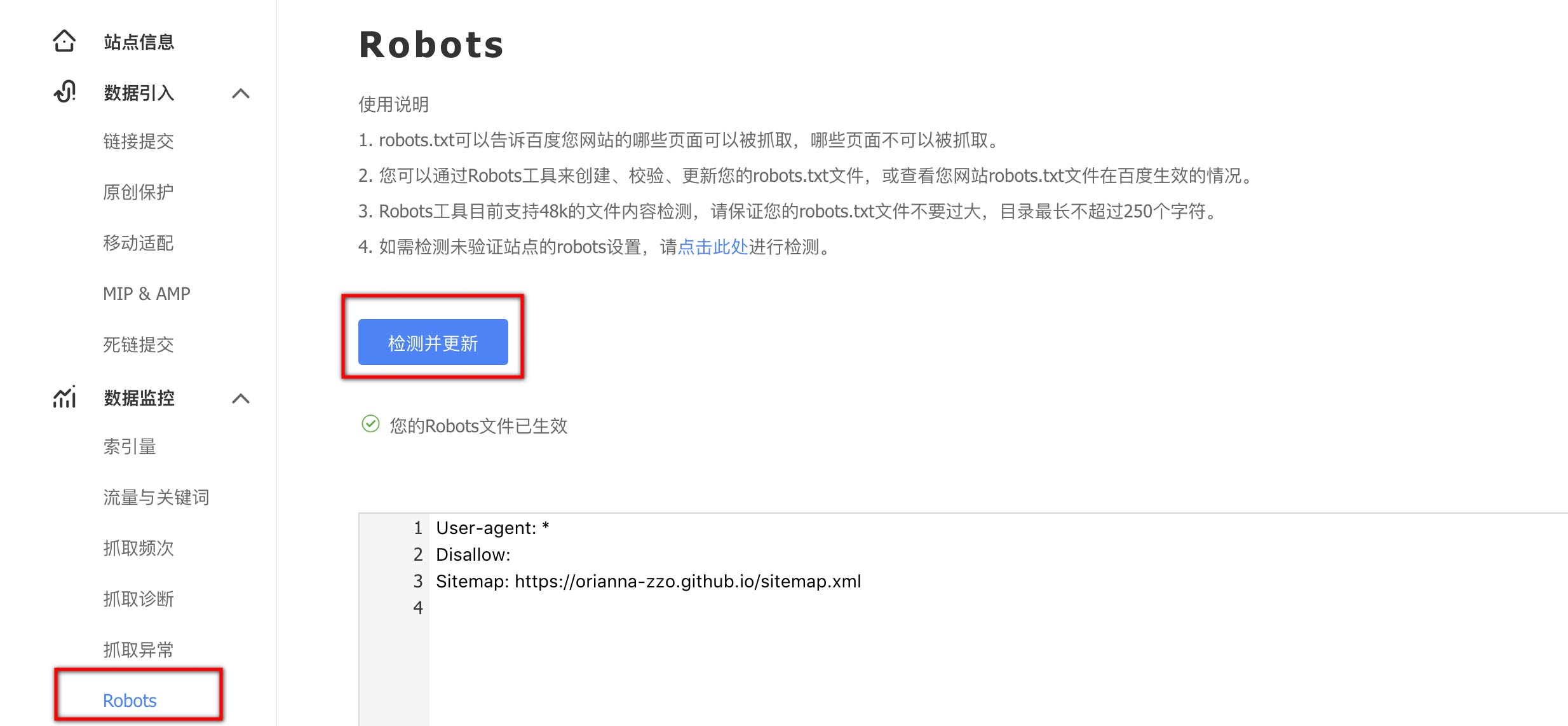
在右侧选择“数据监控>Robots”,并点击检测并更新刷新robots设置。
在“数据引入>链接提交”中的自动提交选择sitemap,并提交sitemap地址。
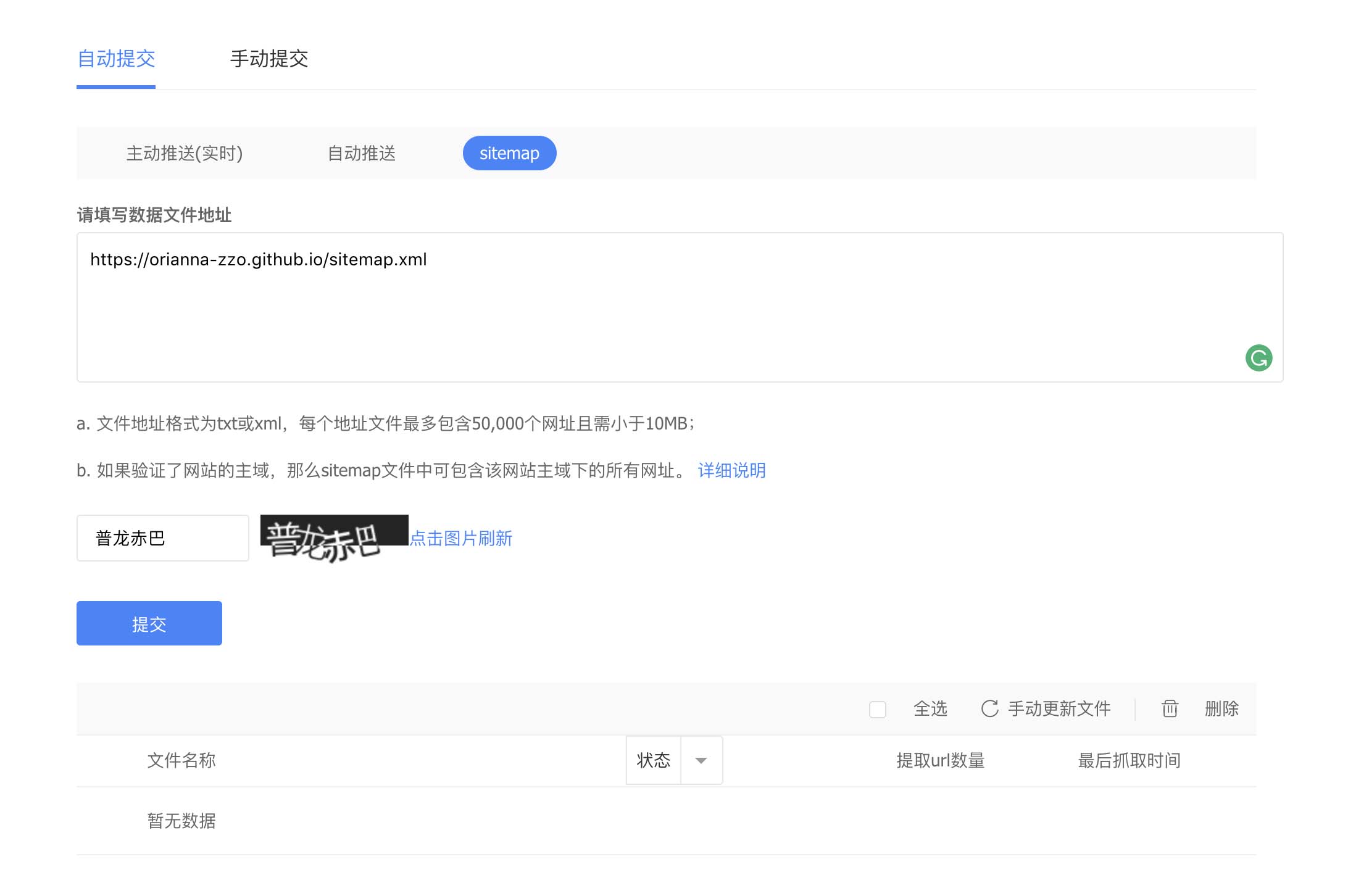
状态转了很久显示抓取失败T^T。
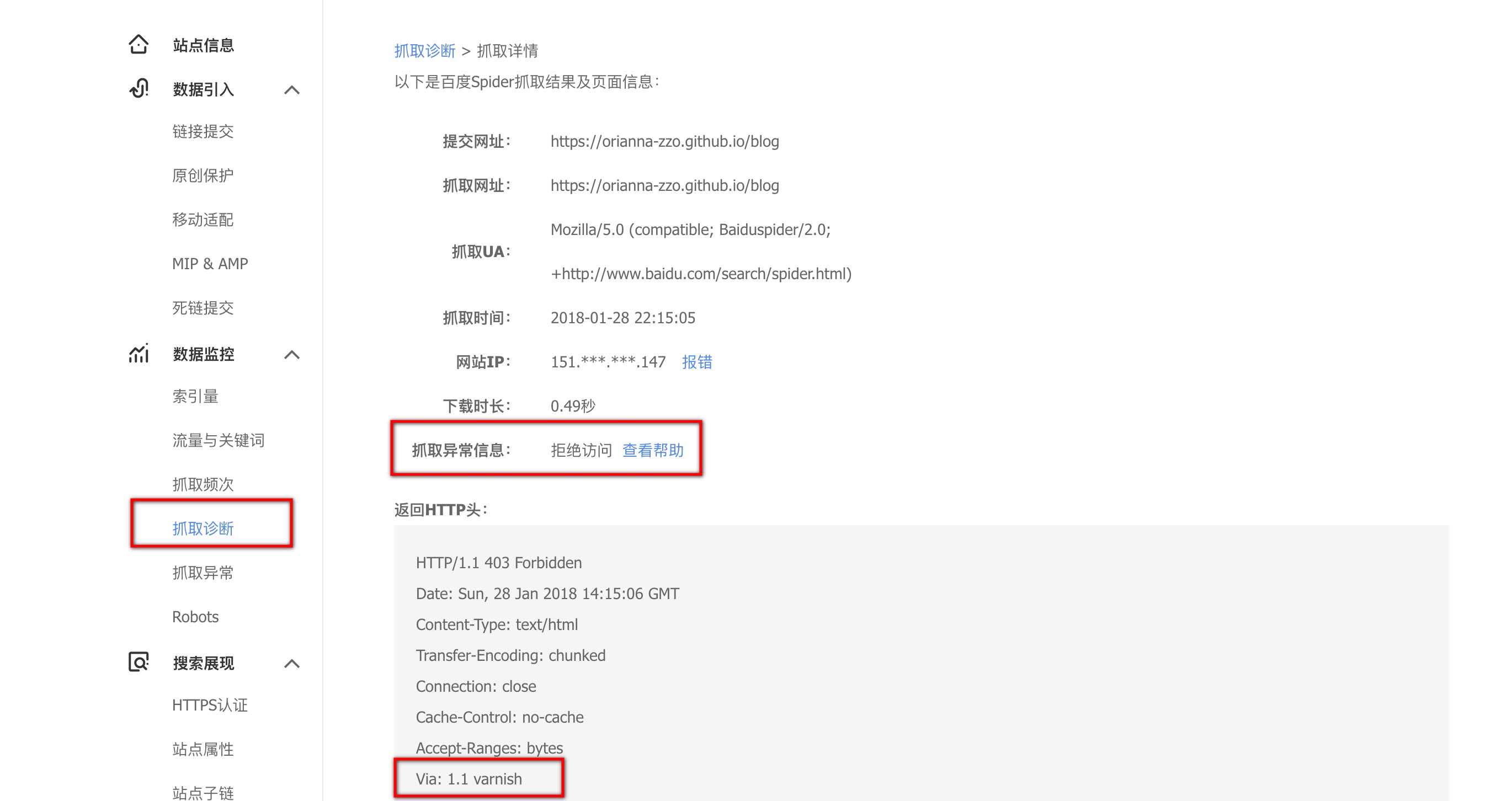
然后选择“数据监控>抓取诊断”,并输入博客网址进行抓取。然后发现,全部都抓取失败了,显示是“拒绝访问”。果然是真的屏蔽了百度爬虫了呀。
Resource资源链接汇总
版本控制
| Version | Action | Time |
|---|---|---|
| 1.0 | Init | 2018-01-28 |